Building a Browser Extension OSINT Tool Because Google Failed Me

Or: How a malicious Chrome extension investigation at work led to an open-source tool
The Extension That Started It All
A few months back, I was working on a security investigation at work. We had hundreds of blocked requests in our logs, all beaconing to what Zscaler flagged as a known malware domain. The suspected source? A browser extension.
I had the extension ID, but here's where I hit a wall:
- The Web Store was blocked on our corporate network
- Google search wasn't helping—just returning generic "how to install extensions" articles
- Searching for any kind of "browser extension lookup tool" came up empty
So there I was, trying to look up this extension on my phone because I had no other option. Not exactly ideal when you're trying to investigate a potential security incident.
I made a note: "possible tool - extension ID lookup." Then, like many of my "I should build this" ideas, it sat in my notebook for a few months.
From Frustration to Solution
Fast forward a few months. I'm cleaning out my notes and stumble across that scribbled reminder. The frutration came flooding back—why doesn't this tool exist? Surely other SOC analysts have run into this same problem?
Time to build it.
Now, I'm not going to pretend I'm some coding wizard. I leaned heavily on Claude (Anthropic's AI assistant) to help me work through the technical challenges. Between my security experience knowing what the tool needed to do and Claude's help with the implementation details, we turned this idea into reality.
The First (Wrong) Approach
My initial plan was ambitious and, in retrospect, kind of dumb. I was going to:
- Build a massive scraper that would crawl ALL browser extension stores
- Index every single extension into a giant database
- Create a frontend that would search this pre-built database
Sounds reasonable, right? Here's why it wasn't:
Problem #1: New extensions are published constantly. How do you keep that database current?
Problem #2: Storage. We're talking potentially millions of extensions across three major stores.
Problem #3: Most extensions would never be searched for. Why store data nobody needs?
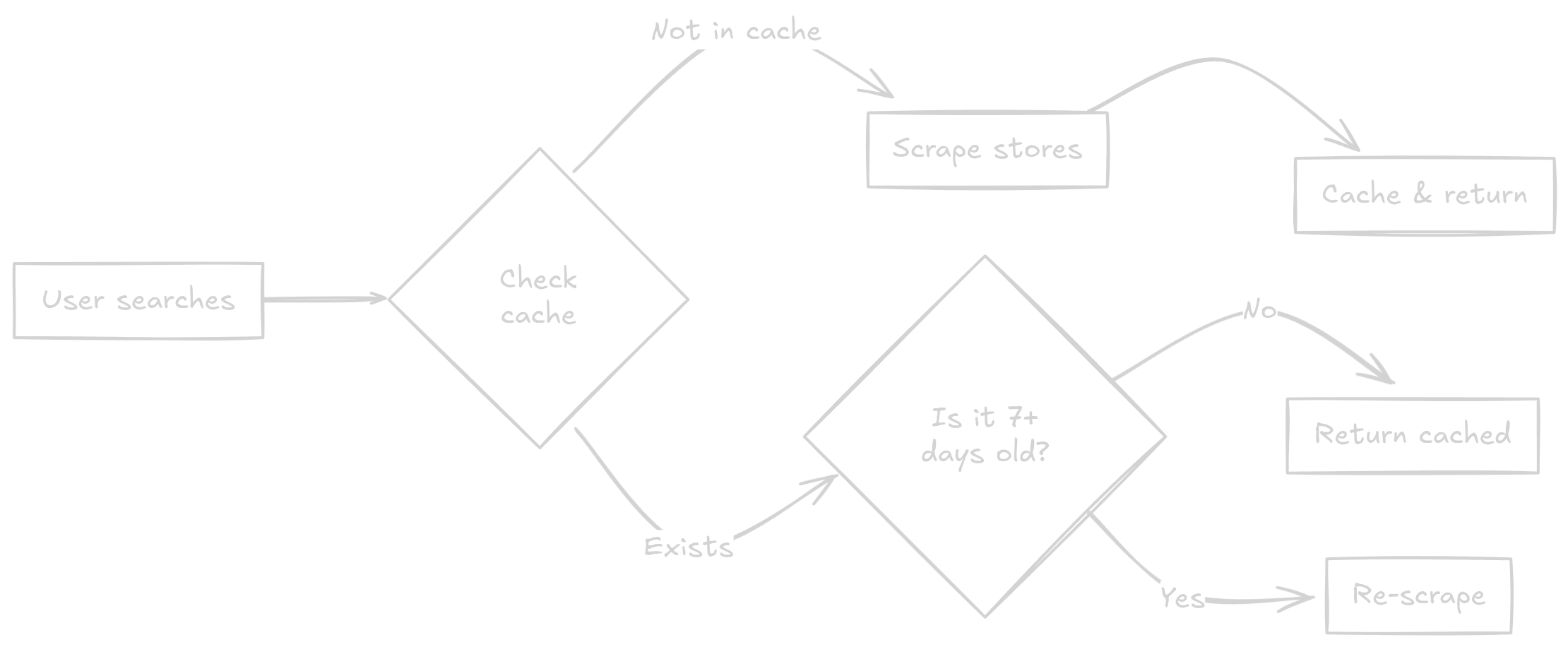
So I pivoted to what I call the "on-demand" approach. Here's how it works:
- User searches for an extension ID
- System checks if we've already cached it from a previous search
- If the cached data is older than 7 days, it automatically re-scrapes for fresh data
- If not cached at all, it goes and fetches the data right then and there
- Results get cached for future searches
Simple, efficient, and it only stores data that someone actually cared enough to look up.
The 7-day refresh is important—extension IDs can get reused, and malicious actors sometimes hijack legitimate extensions. You don't want to be looking at outdated information when investigating a potential security incident.
The Wild World of Extension IDs
Here's something I learned the hard way: browser extension IDs are like snowflakes—no two stores handle them the same way.
Chrome: The Strict Parent
Chrome demands exactly 32 lowercase letters. Not 31. Not 33. Exactly 32, and they better be lowercase.
Input: CJPALHDLNBPAFIAMEJDNHCPHJBKEIAGM
Chrome says: "I'll take that, but only as: cjpalhdlnbpafiamejdnhcphjbkeiagm"
The validation regex is beautifully simple: ^[a-z]{32}$
Firefox: The Free Spirit
Firefox, on the other hand, is like that cool teacher who lets you turn in assignments in whatever format you want. Their IDs can be:
- Email-style:
uBlock0@raymondhill.net - UUID format:
{d10d0bf8-f5b5-c8b4-a8b2-2b9879e08c5d} - Simple strings:
dark-reader
My validation for Firefox? Basically "does it exist and is it longer than one character?" That's it. Firefox gonna Firefox.
Edge: The Middle Child
Edge tries to find a balance. They want alphanumeric characters, at least 20 of them. No special characters, but they're flexible on the exact length.
Validation: ^[a-zA-Z0-9]{20,}$
This difference in ID formats told me something important: each store has its own philosophy about how extensions should be identified. Chrome wants uniformity, Firefox embraces chaos, and Edge splits the difference.
The Scraping Challenge
Now here's where things got really interesting. Each browser store is built differently, which meant I needed three completely different scraping strategies.
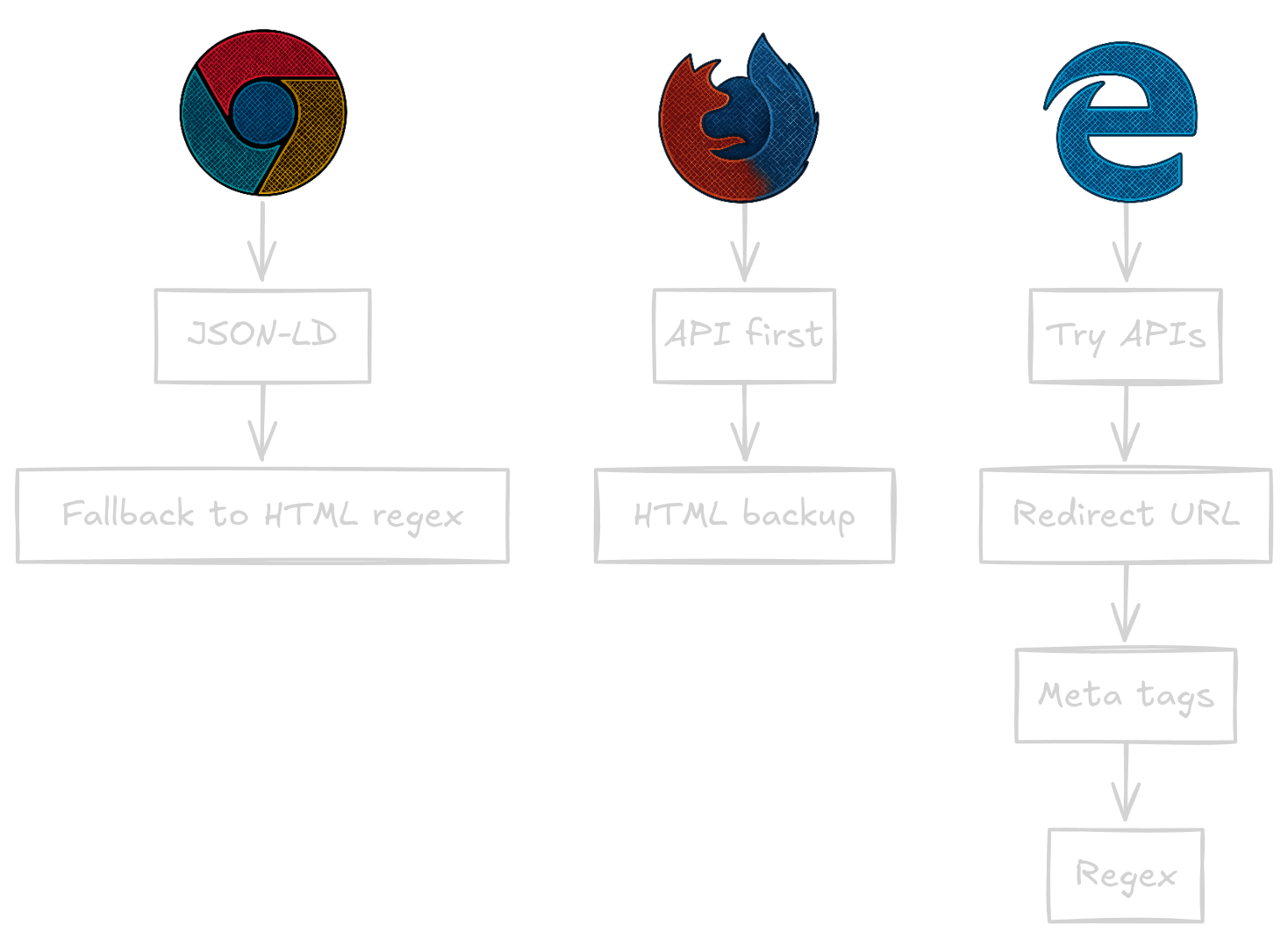
Chrome: The Predictable One
Chrome embeds structured data (JSON-LD) right in their HTML. It's like they're actually trying to help developers out. My scraper first looks for this goldmine of structured data:
# First, let's check for the easy win
json_ld = soup.find('script', type='application/ld+json')
if json_ld:
# Jackpot! Parse the JSON and we're done
If that fails (which it sometimes does), I fall back to good old regex pattern matching on the HTML. Not elegant, but it works.
Firefox: The API Hero
Firefox is the real MVP here. They have a public API! An actual, documented, returns-JSON-data API:
https://addons.mozilla.org/api/v5/addons/addon/{id}/
This is every developer's dream. Clean JSON responses, consistent data structure, no HTML parsing needed. Of course, I still built an HTML scraper as a fallback because, well, APIs go down sometimes.
Edge: The Difficult One
Oh, Edge. Sweet, frustrating Edge. Their add-ons store is heavily JavaScript-rendered, which means when you fetch the page, you get a skeleton of HTML that's about as useful as a chocolate teapot.
My approach here got creative:
- First, try some undocumented API endpoints I discovered (they usually don't work)
- Use the redirect URL format to get to the actual extension page
- Extract what I can from Open Graph meta tags
- Use multiple regex patterns to dig through whatever JavaScript-rendered content made it to the initial page load
It's not pretty, but it gets the job done. Mostly.
Lessons Learned
Building this tool taught me a few things:
1. Sometimes the simple solution is the right one. My "on-demand" caching approach ended up being way better than trying to index the entire internet's browser extensions.
2. Every platform has its quirks. Understanding why Chrome, Firefox, and Edge handle IDs differently helped me build better scrapers for each.
3. APIs are a gift. Seriously, Firefox, thank you for having a public API. Chrome and Edge, take notes.
4. Real problems make the best projects. This tool exists because I had a real pain point during an actual security investigation. That frustration drove the entire design.
What's Next?
The tool is live at browsereidtool.iamjoshgilman.com and the code is on GitHub.
Right now, the Edge scraper is still returning "unknown" for some fields (looking at you, ratings), but it's functional enough to be useful. I'm actively working on improvements, and I'd love to see how other security folks use it.
Some ideas I'm kicking around:
- Bulk analysis features for enterprise security teams
- Historical tracking to see how extensions change over time
- Permission analysis to flag potentially risky extensions
- API integration for automated security workflows
The Bottom Line
Next time you're investigating a suspicious browser extension and can't access the Web Store because of corporate policies, or when Google search is being absolutely useless—this tool has your back.
Because nobody should have to investigate security incidents on their phone.
Found this useful? Star the GitHub repo or reach out if you have ideas for improvements. Always happy to hear how fellow security folks are using the tool in the wild.